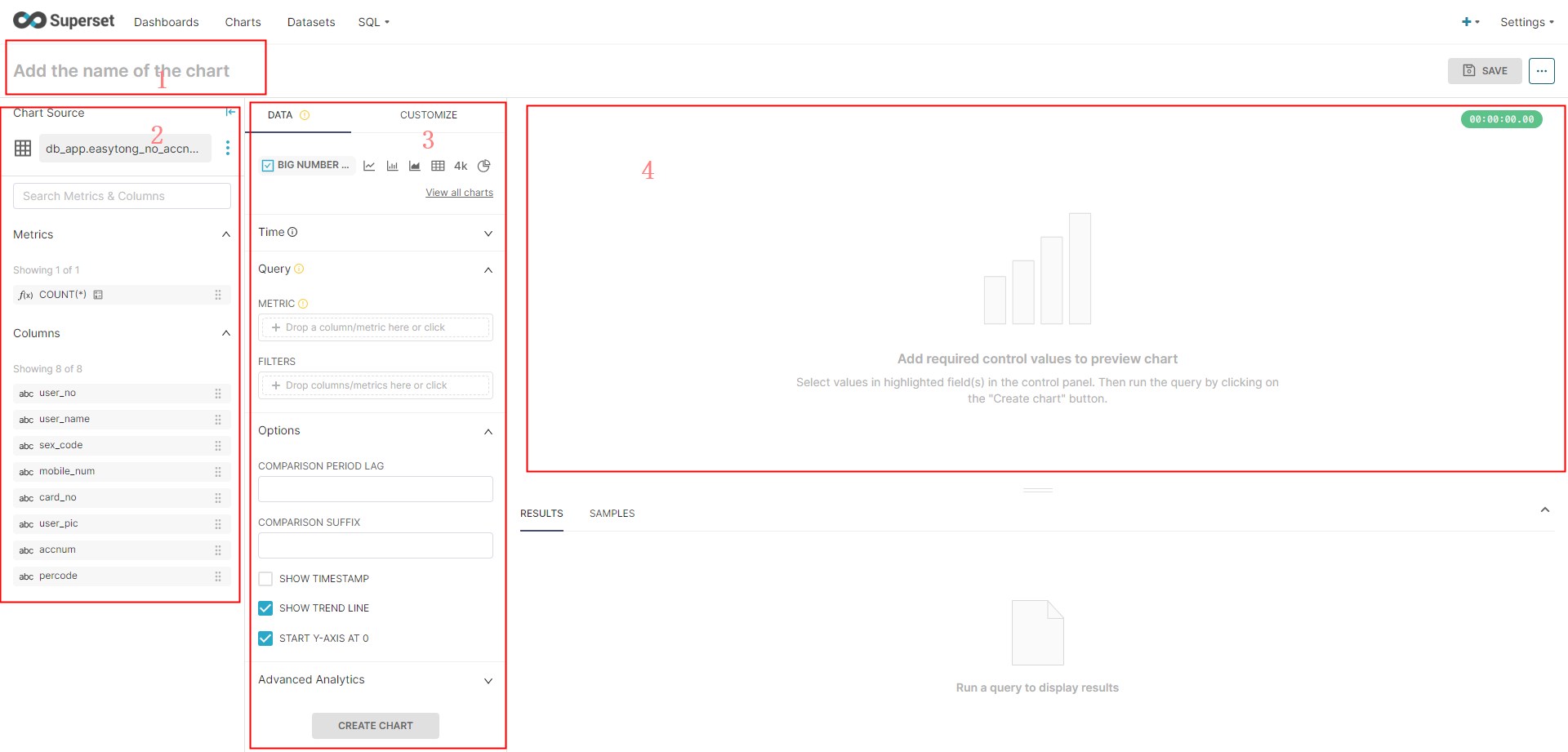
前言
之前我有写过一篇文章,讲述的是怎么使用Dynamic-TP 做一些节省开发的一些问题,但是我感觉不能就直接这么算了,我还想看一下这个框架的一些内部逻辑,避免鸽太久自己以及忘了这回事情或者是还要花比较大的学习成本重新看一下源码,所以我打算花点时间狠狠的看下源码,整理一下自己认为有用的信息,毕竟要知其然更要知其所以然嘛~
我阅读的Dtp源码是1.1.9
之前使用Dynamic-TP 主要是为了使用它的以下功能:
动态调参
实时监控
通知告警
告警拓展
框架自带线程池
线程池注册
其他
所以我也打算从以下几个方面看下相关的一些源码
1、动态调参
虽然动态调参JDK1.8就自带的,但是实际上的Dynamic-TP动态调参实际上有一定的修改的
据我观察Dynamic-TP使用的是这组代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private static void doRefresh (ExecutorWrapper executorWrapper, DtpExecutorProps props) { ExecutorAdapter<?> executor = executorWrapper.getExecutor(); doRefreshPoolSize(executor, props); if (!Objects.equals(executor.getKeepAliveTime(props.getUnit()), props.getKeepAliveTime())) { executor.setKeepAliveTime(props.getKeepAliveTime(), props.getUnit()); } if (!Objects.equals(executor.allowsCoreThreadTimeOut(), props.isAllowCoreThreadTimeOut())) { executor.allowCoreThreadTimeOut(props.isAllowCoreThreadTimeOut()); } updateQueueProps(executor, props); if (executorWrapper.isDtpExecutor()) { doRefreshDtp(executorWrapper, props); return ; } doRefreshCommon(executorWrapper, props); }
doRefreshPoolSize()方法是修改核心线程数和最大线程数,期间涉及到核心线程是是要不如最大线程数大的,不然会报问题,最终调用JDK的修改参数的方法(不过实际上ThreadPoolExecutor本身就是支持校验核心线程数和最大线程数之间比较的)Objects.equals(executor.getKeepAliveTime(props.getUnit()), props.getKeepAliveTime()))是由于配置文件里面默认是TimeUnit是秒,所以此处的比较还是根据秒做比较,当然Dynamic-TP自己有自己的线程池
由于是修改的非核心线程的最大保活信息,底层修改的时候,会使用LockSupport、CAS方式关掉线程池(JBoss),或者是通过ReentrantLock遍历关闭对应超过最大时间的线程(Tomcat)
修改queue的时候,如果是内存安全线程则会修改最大使用内存,如果不相等才会修改任务队列;此外会修改 [OrderedDtpExecutor] 的信息
方法doRefreshCommon修改了拒绝策略等信息,并且如果有配置事件
AbstractDtpAdapter类监听了配置更新的事件,只有配置更新的时候才会调用以上的方法。出发方式的话,如果是nacos的话,则会通过某种方式实现的发布事件让Java程序监听。
该方式在CloudNacosRefresher中
1 2 3 4 5 6 @Override public void onApplicationEvent (@NonNull ApplicationEvent event) { if (needRefresh(((EnvironmentChangeEvent) event).getKeys())) { refresh(environment); } }
2、实时监控
实时监控是通过DtpMonitor类实现的,此处实际上就是通过Spring的事件机制进行事件监控与触发。DtpMonitor自带一个定时任务线程池,最大线程数只有一个。DtpMonitor继承了OnceApplicationContextEventListener抽象类,这个类实现了以下方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public void onApplicationEvent (ApplicationEvent event) {if (isOriginalEventSource(event) && event instanceof ApplicationContextEvent) { if (event instanceof ContextRefreshedEvent) { onContextRefreshedEvent((ContextRefreshedEvent) event); } else if (event instanceof ContextStartedEvent) { onContextStartedEvent((ContextStartedEvent) event); } else if (event instanceof ContextStoppedEvent) { onContextStoppedEvent((ContextStoppedEvent) event); } else if (event instanceof ContextClosedEvent) { onContextClosedEvent((ContextClosedEvent) event); } } }
onContextRefreshedEvent、onContextStartedEvent、onContextStoppedEvent、onContextClosedEvent是Dynamic-TP需要的事件,不过DtpMonitor只实现了onContextRefreshedEvent方法
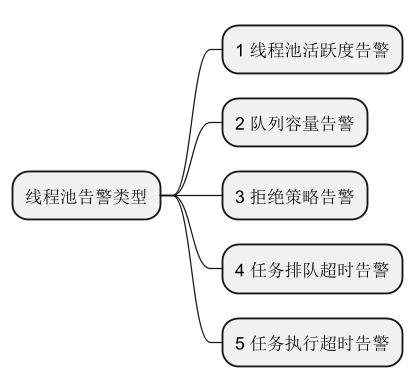
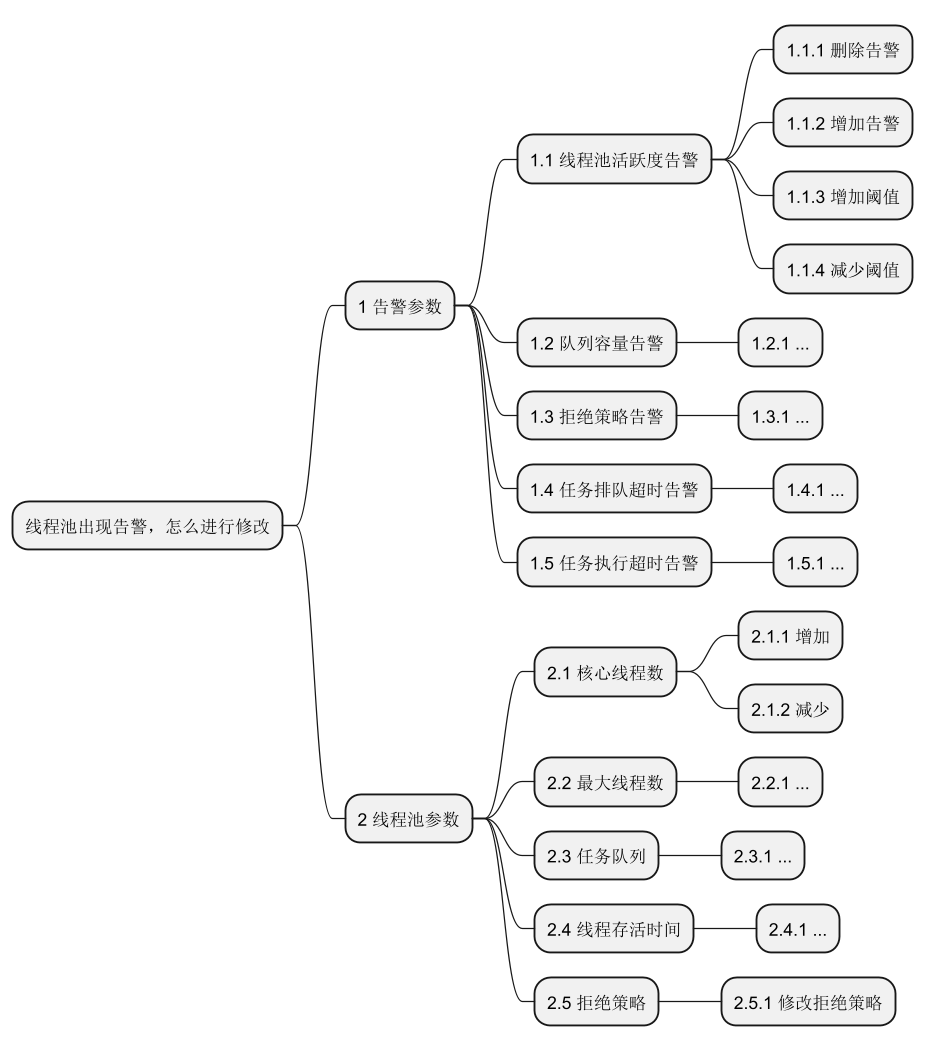
onContextRefreshedEvent会起一个0秒后启动的定时任务,这个任务会给全部的注册在DtpRegistry的线程池发告警消息,AlarmManager会使用自己对象中的线程池ALARM_EXECUTOR进行发布告警消息,告警消息我看只有查看线程活度和任务队列容量,遍历进行告警。
此处使用了spring的事件机制,这个使用来说就是现在存在事件和事件监听器,只要逐注册一个事件监听器,实现 ApplicationListener接口,接口泛型是 你想监听的类。
只要ApplicationContext发布一个你想监听的类的对象,对应想监听这个类的监听器就能监听到,做对应的事情,不过范围只是Java程序内的,做不到分布式的。Dynamic-tp中OnceApplicationContextEventListener就是我们需要监听的事件
言归正传,实际上就是起一个任务分别发布告警和监控的事件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private void run () { Set<String> executorNames = DtpRegistry.getAllExecutorNames(); checkAlarm(executorNames); collectMetrics(executorNames); } private void checkAlarm (Set<String> executorNames) { executorNames.forEach(name -> { ExecutorWrapper wrapper = DtpRegistry.getExecutorWrapper(name); AlarmManager.tryAlarmAsync(wrapper, SCHEDULE_NOTIFY_ITEMS); }); publishAlarmCheckEvent(); } private void collectMetrics (Set<String> executorNames) { if (!dtpProperties.isEnabledCollect()) { return ; } executorNames.forEach(x -> { ExecutorWrapper wrapper = DtpRegistry.getExecutorWrapper(x); doCollect(ExecutorConverter.toMetrics(wrapper)); }); publishCollectEvent(); }
我们分别查看,发出的监控和告警都会到达DtpAdapterListener类,该类会在以下方法中监听对应事件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public void onApplicationEvent (@NonNull ApplicationEvent event) { try { if (event instanceof RefreshEvent) { doRefresh(((RefreshEvent) event).getDtpProperties()); } else if (event instanceof CollectEvent) { doCollect(((CollectEvent) event).getDtpProperties()); } else if (event instanceof AlarmCheckEvent) { doAlarmCheck(((AlarmCheckEvent) event).getDtpProperties()); } } catch (Exception e) { log.error("DynamicTp adapter, event handle failed." , e); } }
处理时会先看是否有DtpAdapter的实现类对于对应的线程池,发送对应的告警,注意DtpAdapter只会对告警做发送,筛选什么的还是在alarm模块里面做。
数据采集会有一个专门的类CollectorHandler用于处理数据采集,这个数据采集也是调用一个类,遍历collectorTypeList的时候调用该方法,会有具体实现类进行实现的。
怎么进行告警的?
通过eventBus(虽然据说是做出来给Android用的,发布者需要使用post(),然后需要一个接收的,通过使用@subscirbe进行event类型的获取,怎么看是否是拿到了合适的,需要通过实现applicationevent后,接受提需要入参是对应类型的event类才能拿到,这种方法一般是void方法)
dynamic-tp中自定义event是这么写的
1 2 3 4 5 6 public class CustomContextRefreshedEvent extends EventObject { public CustomContextRefreshedEvent (Object source) { super (source); } }
在dtpMonitor中,会获取刷新配置的时间,通过这种方式(我才创建的时候会在lifecycle里面先创建时间与事件监听,再发布一个刷新配置的事件)会DtpMonitor中创建一个定时任务,这个定时任务会发布一个AlarmCheckEvent的事件
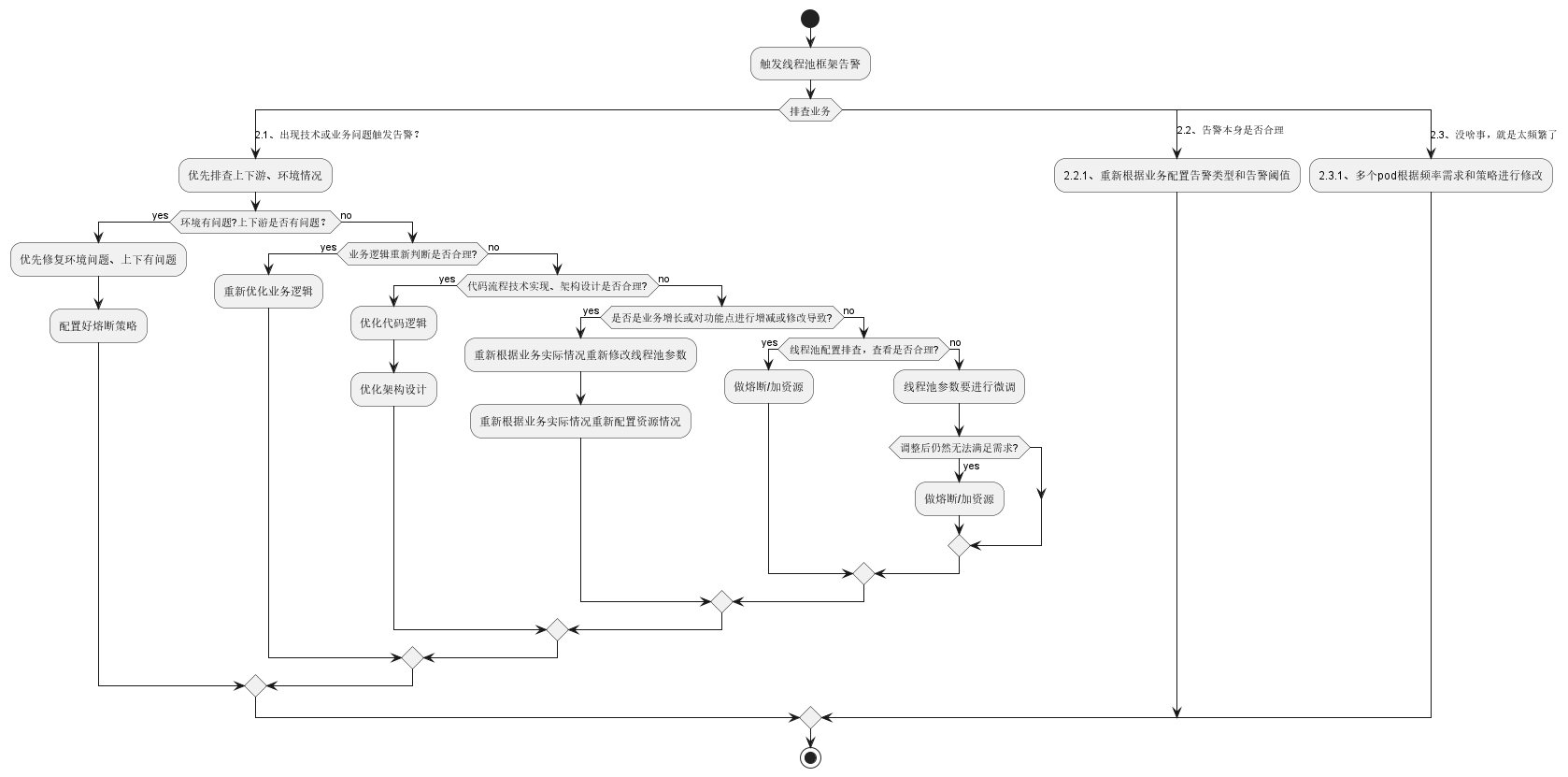
此处会发现它指向了这个context ->相关的代码段,在这个代码段中,会获取全部的dtpadpter(因为第三方组件也会可能使用dtp组件),获取全部dtpadpter的全部线程池wrapper(通常存放着线程池的信息以及一些通知平台和告警项),接着会对全部线程池wrapper查看liveness和capacity,如果到了时间且出发了liveness和capacity,则会进行通知告警,走通知告警的逻辑。
liveness的判断逻辑就是单纯的除法
3、通知告警
告警主要是看AbstractNotifier、AlarmManager这两个Java类。
AbstractNotifier用于处理发送功能,该方式解决了通过send()方法实现发送调参通知、发送告警通知、创建告警内容、创建通知内容、通过MDC获取trace信息、配置receiver的信息(发送调参通知、发送告警通知会使用)、高亮、获取Const类里面的文本信息。
AbstractNotifier类本身是继承了DtpNotifier,DtpNotifier只存储平台信息、发送告警信息、发送变更信息。其他通知类的具体实现类则是实现了send方法,当然也可以实现其他方法。
AlarmManager类里面给IOC容器注册了一个线程池,最大线程数量就1个,任务队列数量是2000个、NoticeManager则是创建了一个任务队列是100个的线程池,一开始创建该类时候会分别执行一次static方法块中的方法,为的是创建过滤器查看哪些平台需要通知。我们以AlarmManager为主要学习类。
值得学习的事情是,遍历该告警那些平台选择过滤条件的时候是从末往前遍历,在更细化一层的时候拿到的信息如果没有的话,会优先使用上一层的信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 @SafeVarargs public static <T> InvokerChain<T> buildInvokerChain (Invoker<T> target, Filter<T>... filters) { InvokerChain<T> invokerChain = new InvokerChain <>(); Invoker<T> last = target; for (int i = filters.length - 1 ; i >= 0 ; i--) { Invoker<T> next = last; Filter<T> filter = filters[i]; last = context -> filter.doFilter(context, next); } invokerChain.setHead(last); return invokerChain; }
是在InvokerChainFactory类中做的过滤,常见的过滤方式存储在AlarmBaseFilter/NoticeBaseFilter/NotifyRedisRateLimiterFilter中,我们当前只看AlarmBaseFilter。
AlarmBaseFilter做过滤操作的时候,会需要ALarm的上下文信息(AlarmCtx,就是存储通知信息以及哪个线程池需要做通知)、Alarm的触发器(AlarmInvoker会配置对应的上下文信息,发送对应alarm信息,重置告警的触发条件,告警信息存储在ConcurrentHashMap,是线程安全的。AlarmCounter),
一开始就会调用invoke方法?
本身是实现了一个链表的invoke的实现,最终创建了一个invokeChain
这句话可能会去掉。配置文件DtpBaseBeanConfiguration会创建一个DtpLifecycle,DtpLifecycle会从注册器中取的全部的注册在DTPRegistry中executor的对象进行初始化(此处会使用CAS保证线程安全),每个DTP线程池遍历使用DtpLifecycleSupport初始化该线程池ExecutorWrapper,ExecutorWrapper初始化的时候不仅会初始化AwareManger,也会初始化线程池对象,线程池对象初始化会优先使用NotifyHelper初始化自己的通知系统,获取DtpProperties和通知平台信息。因为通过哪个平台通知和触发什么情况的时候通知是解耦的,所以只有 触发解耦的条件 会被用来遍历告警频率限制初始化、告警计数器初始化,这两个对象都会存储一个ConcurrentHashMap。
NotifierHandler和AlarmInvoker、NoticeInvoker相关,NotifierHandler在初始化的时候会默认使用ExtensionServiceLoader获取全部的DtpNotifier的对象,存储在HashMap中
NotifierHandler也会写sendNotice、sendAlarm,这就将其和AlarmInvoker、NoticeInvoker联系起来了。
具体的告警如下所示:
有些告警是通过定时任务去触发的,Dtp使用的是Timer时间轮做的效果,通过使用HashedWheelTimer.run()方法进行查看,如活跃度、队列容量 告警都是适用的这个方式
拒绝策略告警 出发是AwareManager通过beforeReject 方法让AlarmManager进行通知。DtpExecutor线程池用到的RejectedExecutionHandler是经过动态代理包装过的任务队列超时告警、任务执行超时告警 官网上说是通过重写重写ThreadPoolExecutor的execute()方法和beforeExecute()方法实现的。当然现在新版本代码是通过Timer时间轮实现的,在AlarmManager中统一进行查看修改。并且Dtp线程池在创建线程等操作的时候会通过AwareManager主动开启一个任务
高亮是怎么实现的?
如告警过程中,通过buildAlarmContent方法创建内容时候,会执行高亮API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private String highlightAlarmContent (String content, NotifyItemEnum notifyItemEnum) { if (StringUtils.isBlank(content) || Objects.isNull(getColors())) { return content; } Set<String> colorKeys = getAlarmKeys(notifyItemEnum); Pair<String, String> pair = getColors(); for (String field : colorKeys) { content = content.replace(field, pair.getLeft()); } for (String field : getAllAlarmKeys()) { content = content.replace(field, pair.getRight()); } return content; }
会将获取需要高亮的信息(存储在NotifyItemEnum中),进行颜色替换
4、告警拓展
告警拓展具体来讲就是自己写了个新告警,但是新告警需要使用JDK SPI机制,JDK SPI是因为我们传输的Alarm信息不能被IOC容器管理,因为我们是一个告警需要产生一个类的,Spring SPI靠的是将JDK SPI的类加载IOC容器中实现的可加载模式的。
为什么是使用JDK SPI?因为使用Spring SPI是需要托管到IOC容器的,但是NotifierHandler本身会处理告警通知,但是如果如果要做到动态修改配置与个数,则需要做到实时的创建与删除,变成Bean是不够合理的,所以才会使用JDK SPI方式,通过以下方式实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Override public void invoke (BaseNotifyCtx context) { try { DtpNotifyCtxHolder.set(context); val noticeCtx = (NoticeCtx) context; NotifierHandler.getInstance().sendNotice(noticeCtx.getOldFields(), noticeCtx.getDiffs()); } finally { DtpNotifyCtxHolder.remove(); } } public static NotifierHandler getInstance () { return NotifierHandlerHolder.INSTANCE; } private static class NotifierHandlerHolder { private static final NotifierHandler INSTANCE = new NotifierHandler (); } private NotifierHandler () { List<DtpNotifier> loadedNotifiers = ExtensionServiceLoader.get(DtpNotifier.class); loadedNotifiers.forEach(notifier -> NOTIFIERS.put(notifier.platform(), notifier)); DtpNotifier dingNotifier = new DtpDingNotifier (new DingNotifier ()); DtpNotifier wechatNotifier = new DtpWechatNotifier (new WechatNotifier ()); DtpNotifier larkNotifier = new DtpLarkNotifier (new LarkNotifier ()); NOTIFIERS.put(dingNotifier.platform(), dingNotifier); NOTIFIERS.put(wechatNotifier.platform(), wechatNotifier); NOTIFIERS.put(larkNotifier.platform(), larkNotifier); }
可以看到实际上是通过创建一个NotifierHandler进行通知,每次创建都会通过获取通过任何方式提供的DtpNotifier服务,后将其注册到这个创建的NotifierHandler的Map中。
5、框架自带线程池
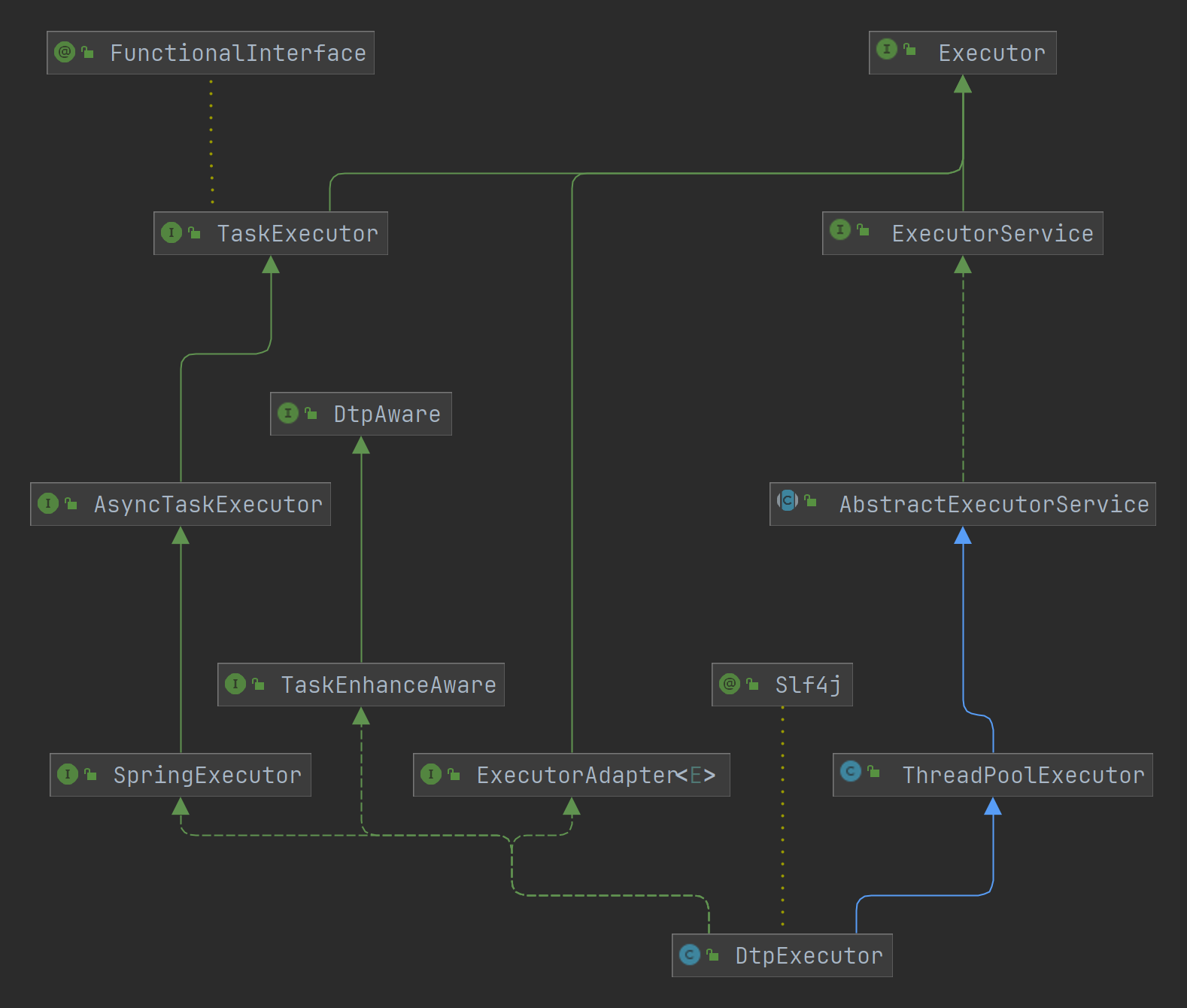
框架自带线程池均继承自DtpExecutor,DtpExecutor继承自ThreadPoolExecutor,顺便实现了SpringExecutor, TaskEnhanceAware, ExecutorAdapter,具体原理是在execute 、beforeExecute 、afterExecute 上面做了增强,包装成了DtpExecutor自己的
源码中,除了Tomcat第三方线程池有不同外,其他的都是如下
1 2 3 4 5 @Override protected void beforeExecute(Thread t, Runnable r) { super.beforeExecute(t, r); AwareManager.beforeExecute(this, t, r); }
可以看到是总是会先调用ThreadPoolExecutor的beforeExecute方法,然后会使用AwareManager.beforeExecute()方法,这个方法会先删除掉原先的Runnable,然后在开启一个新的Runnable,因为要设置线程的期限运行时间,所以会使用Timer时间轮做定时关掉的任务
执行execute方法时候,则必定会调用AwareManager.execute方法,只有被DynamicTp增强后的任务才会被DTP自己加载监控等信息,然后再开启任务。
1 2 3 4 @Override public void afterExecute(Executor executor, Runnable r, Throwable t) { Optional.ofNullable(statProviders.get(executor)).ifPresent(p -> p.completeTask(r)); }
可见也是先调用ThreadPoolExecutor的afterExecute方法,再看对应Executor是否存储在DTP里面,有的话再调用该Executor删除掉对应任务。
6、线程池注册
虽然看起来线程池注册是在整个框架中比较不常见的,但是这个也非常的重要,值得我们学习与阅读。DtpRegistry也继承了OnceApplicationContextEventListener,这代表
线程池注册在DtpRegistry里面,里面的话是一个ConcurrentHashMap
public class DtpPostProcessor implements BeanPostProcessor, BeanFactoryAware, PriorityOrdered
b. 另外就是会将获取DtpRegistry中线程池的一些操作API给放这个类里面了;监听事件刷线配置的操作也存放在这个类里面了。这个刷新方法会同时刷新Dtp线程池和不是Dtp但是托管给了Dtp的线程池。
7、其他
7.1、对接第三方线程池
adapter模块目前已经接入了SpringBoot内置的三大WebServer(Tomcat、Jetty、Undertow)的线程池管理,实现层面也是和核心模块做了解耦,利用spring的事件机制进行通知监听处理。通过initialize()方法拿到webServer的线程池
1 2 3 4 5 6 7 8 9 10 11 @Override protected void initialize () { super .initialize(); if (executors.get(getTpName()) == null ) { ApplicationContext applicationContext = ApplicationContextHolder.getInstance(); WebServer webServer = ((WebServerApplicationContext) applicationContext).getWebServer(); doEnhance(webServer); log.info("DynamicTp adapter, web server {} executor init end, executor: {}" , getTpName(), ExecutorConverter.toMainFields(executors.get(getTpName()))); } }
在这个方法中,doEnhance()方法会修改WebServer的线程池为Dtp自己的线程池,且该线程池会受到对应webserver线程池参数的影响
其他的则和我们在项目中使用的Dtp线程池具体代码实现相差无几
7.2、Dynamic-TP对于Spring的使用
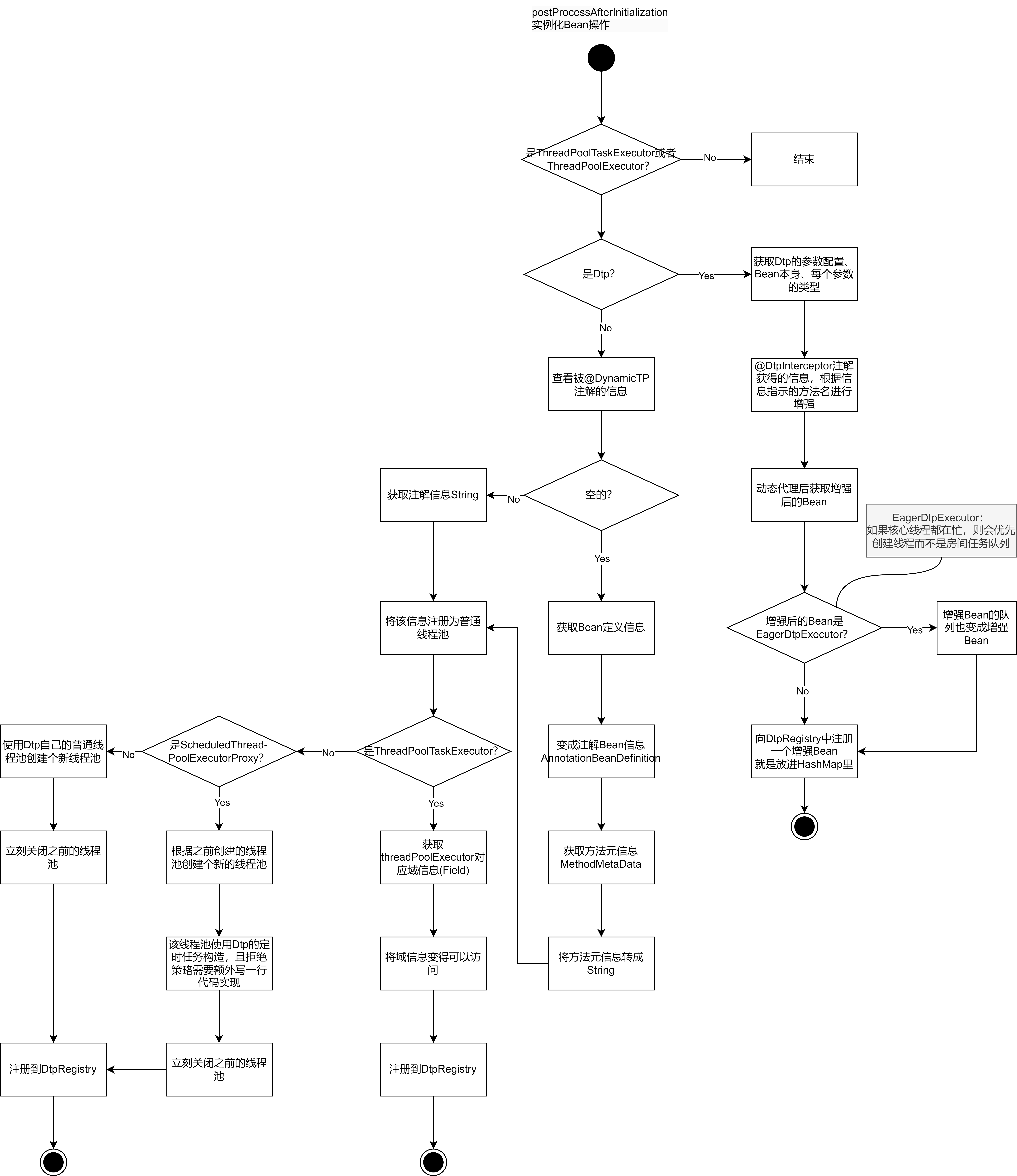
DtpPostProcessor
具体来讲这个类就是在单例化Bean的时候,如果发现不是ThreadPoolTaskExecutor、ThreadPoolExecutor就不做操作,如果是DtpExecutor或者是ThreadPoolTaskExecutor、ThreadPoolExecutor就做一组操作进行包装。
@1:如果bean不是ThreadPoolExecutor或者ThreadPoolTaskExecutor,那么就不对bean做任何处理,直接返回
@2:如果bean是DtpExecutor,调用registerDtp方法填充DTP_REGISTRY这个map
@3:如果说bean上面的DynamicTp注解,使用注解的值作为线程池的名称,没有的话就使用bean的名称
@4:如果bean是spring中的ThreadPoolTaskExecutor的话,那么就通过getThreadPoolExecutor()方法拿到ThreadPoolExecutor注册到COMMON_REGISTRY中
到这里执行完,就针对所有线程池对象完成了增强
看起来复杂实际上简单
AwareManager
这个其实是相当重要的一块,涉及到了以关闭线程池、终止线程池、执行一个任务、注册、添加、更新线程池、拒绝策略为切面实现了一组操作
涉及到监控、触发拒绝等问题,因为线程池是实时在变化的,参数调整、任务的创建和完成等操作,都会涉及到监控指标,拒绝策略的修改,因此为了更好地使用资源,所以才会有AwareManager。
DtpInterceptorRegistry
根据注解@DtpInterceptor获取对应拦截器信息,基于此提供了对应的API
DtpInterceptorProxyFactory
存储着一些动态代理的方法,如getSignatureMap获取注解的信息修改
总结
笔者看了下美团的动态线程池实践,发现了JDK8的线程池的内部维护的逻辑,看起来还是很不错的
内部有个worker,这个worker里面有thread和runnable,所以既有任务又有线程去维护,本身线程池是 内部有很多信息 的
线程池本身有五种状态,其他四种是为了结束线程池而特意准备的
线程有线程状态和线程数量 这俩状态,在高并发的情况下,使用两个变量去存储则会比较麻烦,不如使用一个AotmicInteger,高三位存储线程池中线程状态,低26位存储线程数量。
也有worker的回收线程。
线程池怎么使用,最好还是按照不同业务来分配线程池,避免不同任务之间有父子级关系,导致OOM,也有可能会因为一部分业务占用资源过多导致出现其他业务饥饿的现象
dynamic-tp本身使用了eventBus,我个人觉得很不错。通过使用@subscribe注解实现的,这个注解有些属性,ThreadMode 线程模式,主要是看发布者和订阅者执行的一个方式,posting就是一个发送事件谁执行事件的一种方式。sticky属性类似于广播中的粘性广播。可以先将事件发出,留存在内存中,后面等到有订阅方法时,再接受订阅。priority 优先级可以使得优先级更高的获取到对应信息。
线程池有submit和execute这两者的区别在于execute只能提交Runnable类型的任务;submit既能提交Runnable类型任务也能提交Callable类型任务。
execute会直接报错,需要trycatch,和普通执行任务一样;但是submit会吞掉异常只能通过future.get()拿到对应信息。
execute没有返回值,submit有返回值。
如果提交任务不需要结果的话则不需要使用submit,execute更快
引用文章
dynamictp官网 动态线程池框架(DynamicTp),监控及源码解析篇 SpringBoot:Bean生命周期介绍 Spring Bean的生命周期 Spring揭秘:ApplicationContextAware应用场景及实现原理! 观察者模式Spring之publishEvent事件处理 Java 创建事件(Event)、事件监听器(EventListener)、事件发布(publishEvent)详解和相关demo java中的“&”、“|”、“^”、“~”运算符怎么用? 基于开源的配置中心的轻量动态线程池dynamic-tp实践与源码原理分析 Java 中的定时器类Timer详解 SoftReference 到底在什么时候被回收 ? 如何量化内存不足 ? com.google.common.base.Joiner,谷歌提供的字符串处理工具 applicationContext.getBeansOfType(class)获取某一接口的所有实现类,应用于策略模式简单demo | 掘金 玩转Spring生命周期之Lifecycle和SmartLifecycle SpringBoot的SmartLifecycle生命周期接口 java 非常好用的一个缓存(Google Guava的Cache) https://blog.csdn.net/qq_24654501/category_11384283.html ApplicationEvent 的简介及简单使用 动态线程池DynamicTp系列四之监控告警 SpringBoot实现静态、动态定时任务,本地动态定时任务调度 Google Java编程风格规范(2020年4月原版翻译) 提升编程效率的利器: 解析Google Guava库之集合篇Immutable(一) 事件驱动模型的最佳实践-SpringEvent【(二)原理篇】 【Spring Boot 源码学习】ConditionEvaluationReport 日志记录上下文初始化器 SpringBoot-5.ApplicationListener子接口GenericApplicationListener, SmartApplicationListener 谷歌工具导包-com.google.common.collect Google Collections:Java开发者必备的集合处理库Guava教程 一文读懂Spring的SPI机制 SpringBoot加载自定义yml文件 org.apache.commons.collections4下的CollectionUtils工具类 Java工具库——commons-lang3的50个常用方法)集合开发工具大利器 Spring Aware机制 那些年背过的题目:Spring ApplicationContext- IOC容器初始化过程 一张长图透彻理解SpringBoot 启动原理,架构师必备知识,不为应付面试! beandefinition与beanfactory 面试篇之什么是静态代理?什么是动态代理? Spring IOC容器分析(3) – DefaultListableBeanFactory Timing Wheel 定时轮算法 Java开发利器Commons Lang之元组