背景
我当前是一名普通的 Java 技术开发。人在杭州,目前的行业是安防行业,最近这段时间有想润的想法,有空位的可以加我投递与被投递。喜欢出去玩的同好也可以来找我,我比较喜欢读书,骑行,长跑,羽毛球,探店,其他的爱好我还在持续探索中。
复盘
今年年初还没有学习过目标管理,所以很多目标都没有实现。不过今年学习了,之后肯定可以更好的指定目标与实现目标
跳槽
之前我在杭州某G端产品的企业中工作,22年毕业后一直在那边工作,但是这份工作其实更接近于项目外包,都是在重复重复,对于我而言完全没有什么提升的空间;这让我想到了之前在大学哲学课上老师讲的事情,人的一切发展都是有比较而来的,有近就有远,有宇宙之大就会有原子之小,看到了和我一个学校毕业的人有了很大的成就后,也开始催促我进行成长。因此我在24年4月成功跳槽到当前公司B,期间当然也投递了一些比较知名的厂子。不过因为大厂进不去,也越能证明我的离开的想法是正确的,是应当做的,在面试过程中,多因为我扒股准备的还
行,但是基本上没有很厉害的实战经验。因此在进入新的公司后,有了专业的软件开发流程,我通过积极参与工作,也有学到更多。公司中有了专门的运维团队和测试团队,并且也有同事准备专门的教案进行教课。DBA和ELK专门的同事也有,不像原先的公司,这些岗位要么没有,要么在某一个身兼多职的人身上。
后续只拿了 2 个滨江区的 offer,一个是电商行业的,一个是安防行业的,电商行业的其实是和一个子公司签合同,感觉有点怪,并且人还很少,只有 200 人的一个小公司,安防行业的那个有大概 5k 人,所以选择了入职安防厂子。
2024年基本上也就做了这几个事情:
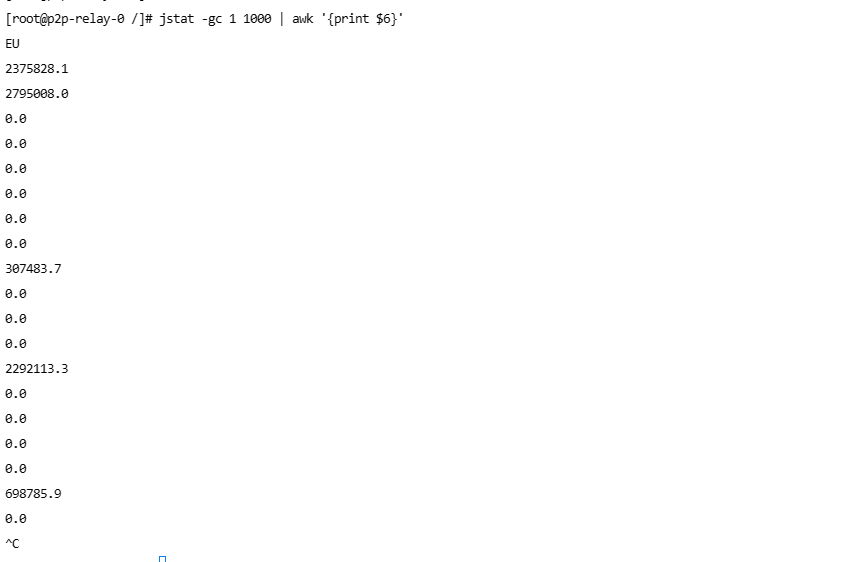
- 事件业务进行了重构改版高并发查询,出现了慢查询,修复了慢查询
- 套餐支持不同类型订阅人使用不同订阅设备
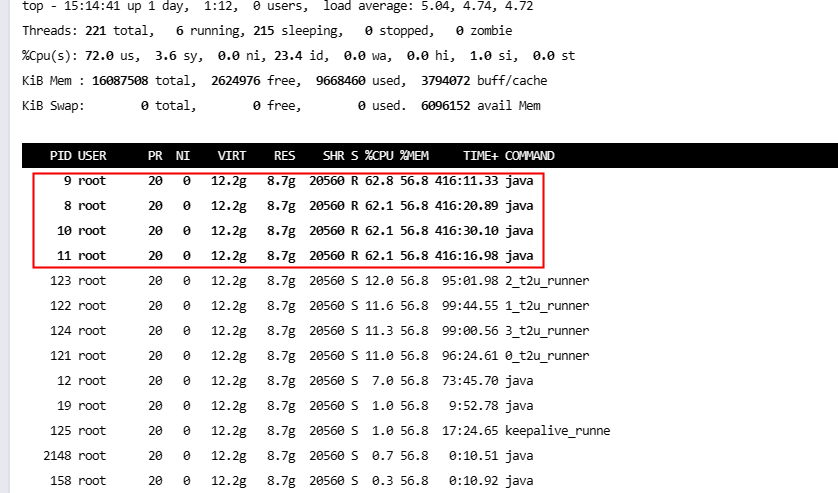
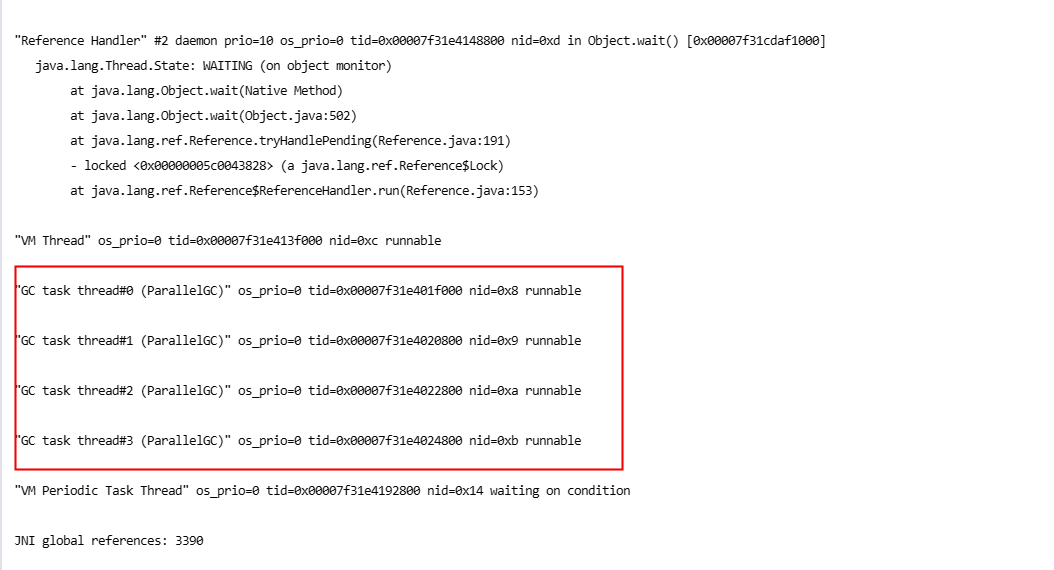
- 服务新增线程池监控告警,使用开源组件基础上又做了一层封装
- 新增事件呼叫业务,新增时间业务的高并发场景下的异步操作与回调操作
- 修复几十个已知的线上bug
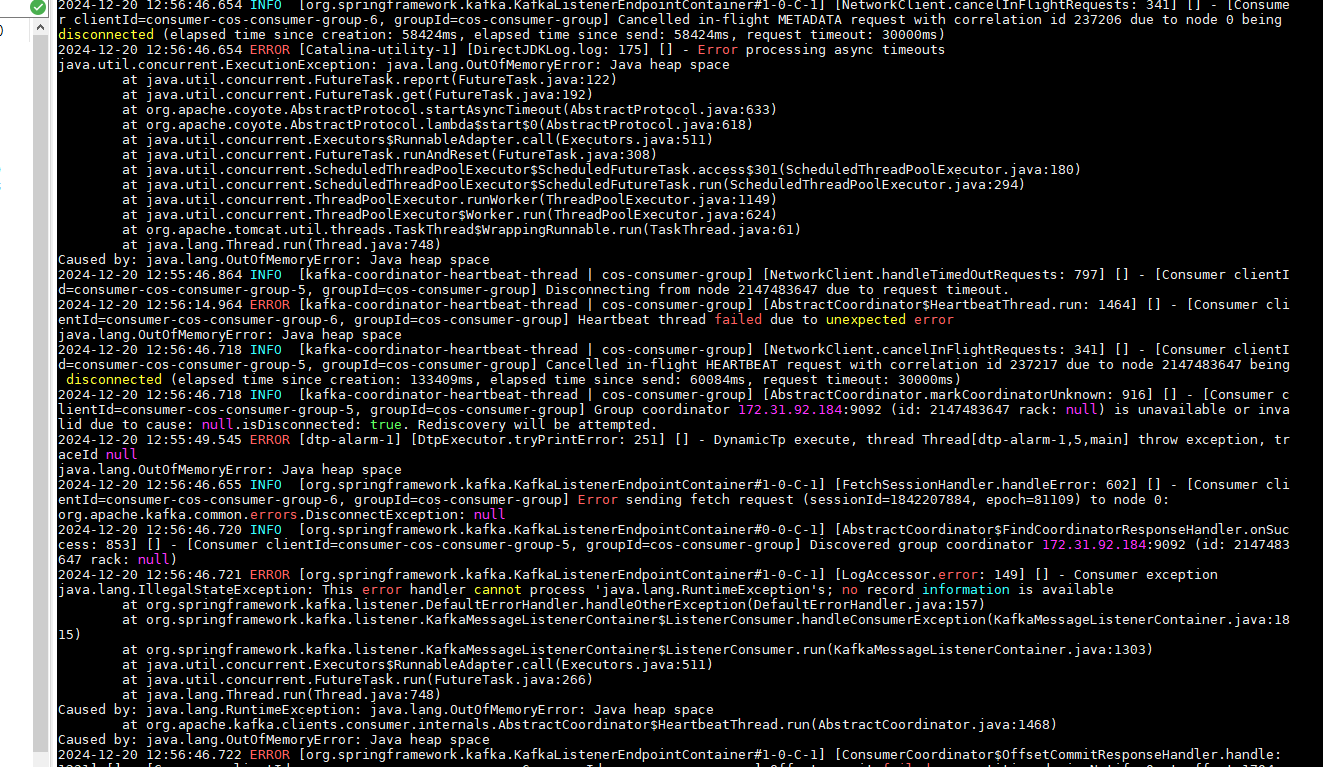
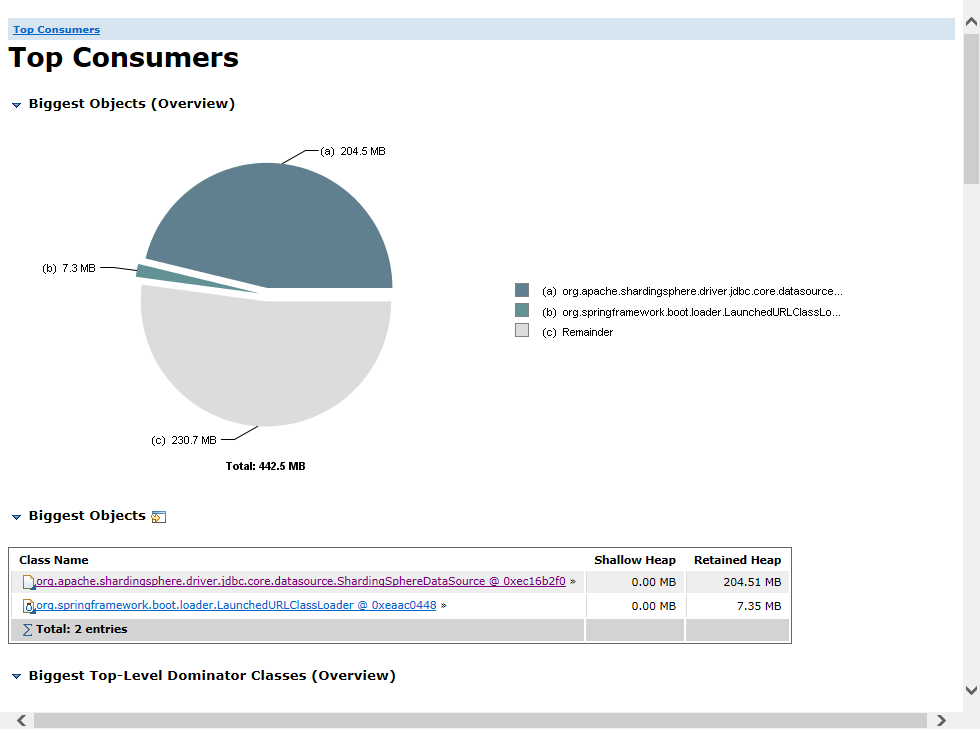
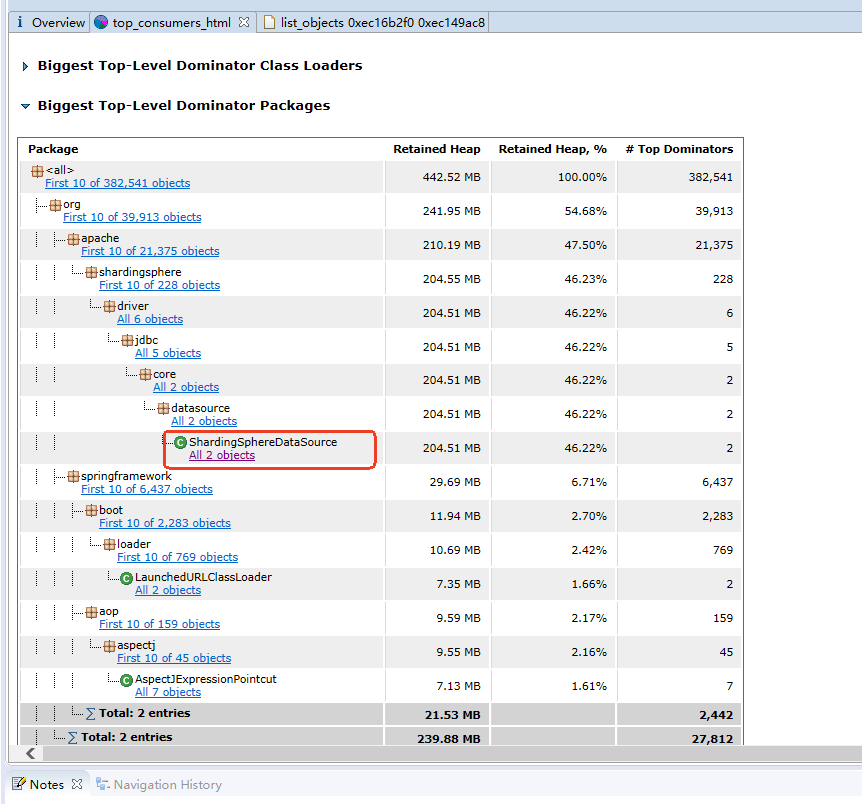
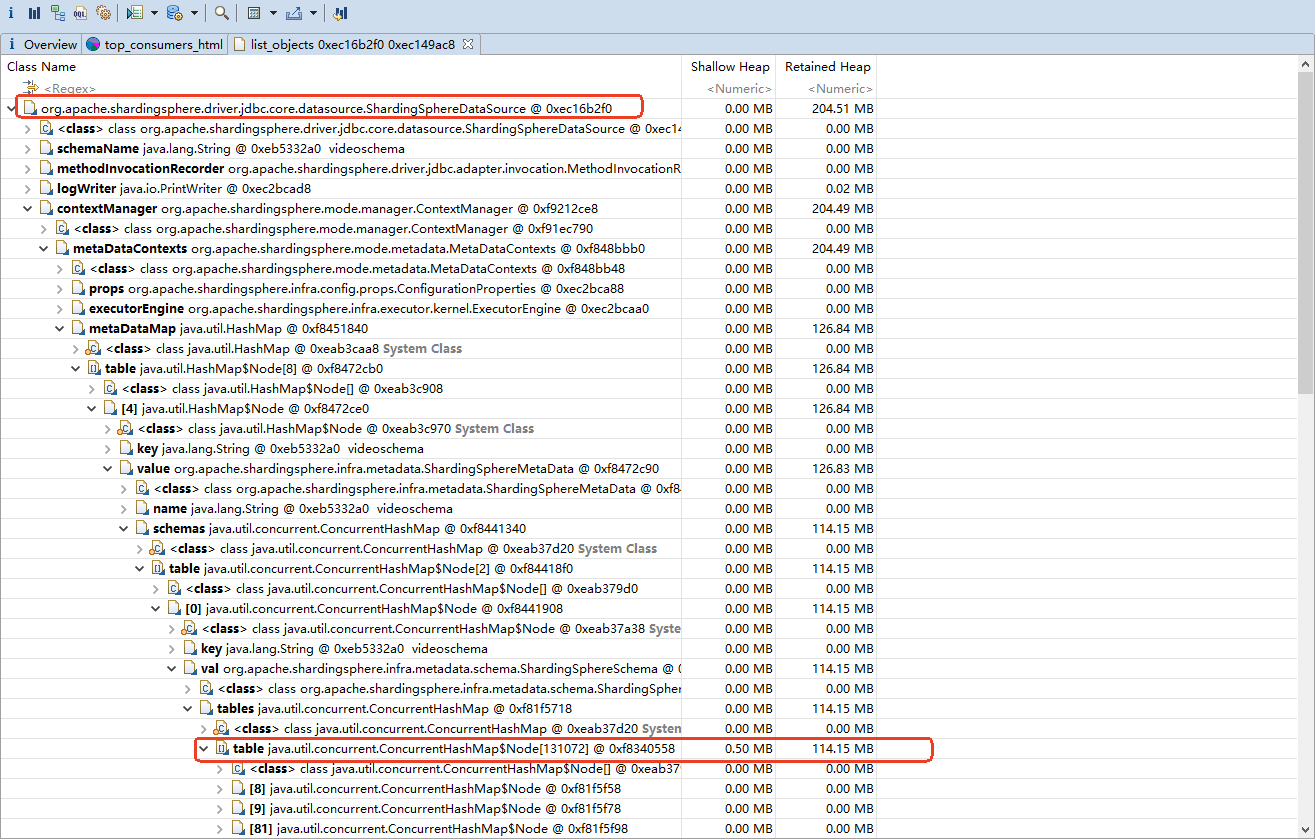
整个开发过程不是开发困难,而是需要走标准化的流程,导致需要做很多归档,以至于我的组长都嫌弃我慢吞吞的 😢 。基本上每天都要加班,我粗略算了下,每个月都要至少加班 45h,感觉长久以来不是好事,我的健康都受到了影响,头发都掉了 1/4 了,可能干一年我就走了。
公司里面使用的是内网电脑,且是B端业务,基本上不能有使用AI直接生成满足业务的代码,但是使用AI生成存储过程进行辅助还是可以的。
新公司使用的技术栈个人认为不是很新,并且如果想要改版,得先让运维、测试、自动化脚本部门服从你的安排进行打通,否则只是个人单纯的使用新功能不能让其他人信服。在新公司中学到了一些其他的知识。今年业务是有所长进,但是技术的话基本上没长进,甚至可能还不如去年,我很喜欢的一个 B 站 up原子能讲过,如果一年下来可以记录在简历里面的东西很少,那代表可能需要离开了,不过当前我学到的东西还是有一些的,我打算先苟上一段时间。
尝试副业
只做程序员是不行的,所以我也打算开启自己的副业之旅,不过当前营收额是0,今年上旬打算是通过写博客赚钱,现在只获得了26个粉丝,csdn上面有200个粉丝,距离可以靠写作赚钱还剩不到9800个。我打算是通过做自己喜欢的事情作为副业进行赚钱,我打算继续把这个事情作为我25年的目标。之前在休闲的公司的时候,一个月可以产出4篇,现在不行了,就算有灵感也没有很多时间查找资料进行整理思考产出了,7月的时候参加了活动,拿了个小小奖。有需要这个打折券的可以找我。


当然还是有几篇稍微有一点人看,我先截个图在这里。
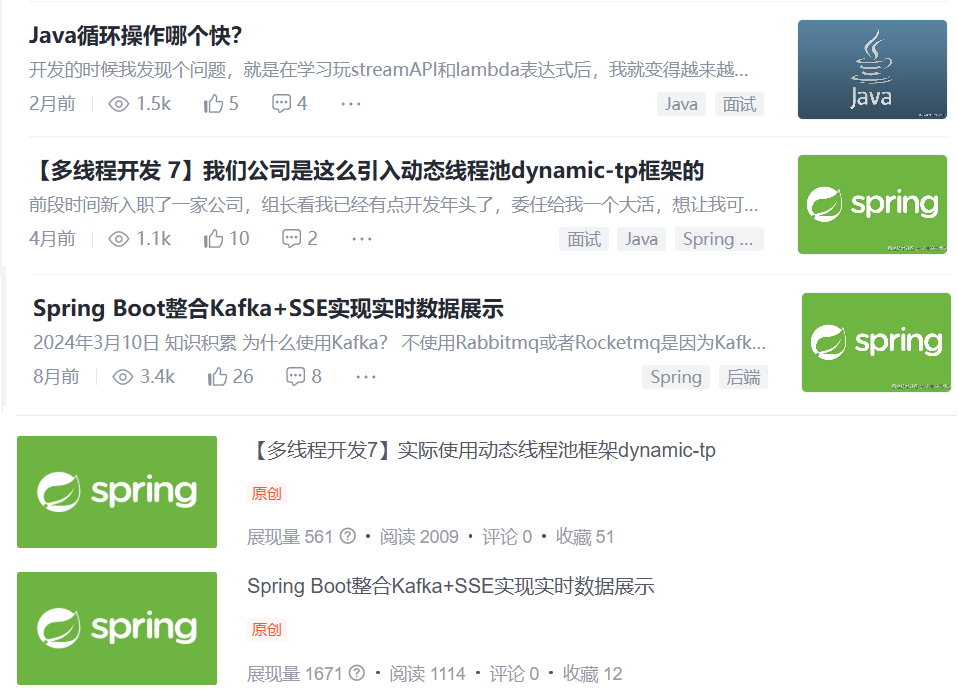
后续我打算不只是做一个只写博客的人,后续我也得通过技术外包等方向发展自己的副业才行。
学习
之前在前东家完全么有什么成长,但是在新公司还是比较培养人的,我也在其他新同事的影响下有了很多个人成长。
自从毕业后,22、23年我也没看过书(技术社科博客会看一点),但是24年我也有学到很多,也看了很多书。今年看了《领域驱动设计》、《优势谈判》、《高效能人士的7个习惯》、《Spring源码深度解析(第二版)》,这些书除了《领域驱动设计》,其他的书对我思想上帮助很大,同时也对于我在实际工作生活中也有很大帮助(《领域驱动设计》有些地方讲的太模糊,对于我的思维构建有点差距,后续我打算看下六边形架构和Cola架构)。我打算后续也多看一些书,帮助自己更好的工作学习生活。纸质书没读多少,但是电子书倒是一本接着一本的看,我现在只要是在地铁上或者是在路上都会看一眼电子书。后续我可能会开一个专栏专门记录一下阅读了哪些书籍,且应用了哪些,取得了什么成果,有什么失败的经历值得回溯。
本来打算今年11月参加高级软考,但是因为工作太忙忘记了,后续我打算学习一下精力管理,保证自己可以在工作之后可以学有余力的进行其他有用的社会活动。
算法做题有做一些,但是没有参加比赛,基本上是拿着大学学到的知识在练习(大学时候主要使用C++写算法,现在却主要在用java写代码),并且主要目的还是为了面试求职。
今年我开始参加各种会议,也浅浅的认识了一些开发者,有些人很谦虚,有些人很开放,这些人都是我可以学习的榜样。参加会议和沙龙,今年主题最多的就是AIGC和cursor,也有人真正的把一些AIGC产品给落地了。
为了通勤我买了辆山地自行车,周末也会骑车到钱塘,滨江,萧山这边走走,平常去的多的地方是湘湖,今年的骑行虽然没让我减少很多体重,但是至少让我对于工作地方有了更好的认识与了解,好吃的地方我也变得一目了然了。 自从进了新公司后,我也搬家了,从快到苕溪的余杭那边搬到了滨江浦沿,从1300能租到30平的朝南带阳台的大房间到现在只有15平的1600的小房间,我都基本上没地方做饭了,一些炒菜我也不方便做,没地方施展拳脚,后面我就只买一些鸡肉和虾这类方便一点的食物来凑活,做饭频率虽然降低了,但是做饭厨具现在减少了很多,变相的让我不需要再去维护很多使用频率低的家具了。
娱乐
我的一个爱好是玩点单机游戏,因此今年玩了1、赛博朋克2077:往日之影(DLC)2024年4月27日、2、艾尔登法环:黄金树之影(DLC) 2024年6月23日 3、黑神话悟空 2024年9月15日
目前有点想玩下永劫无间,不知道最近也没有额外的时间可以用于打游戏了。之前从朋友那边收了个PS5,也买了个血源诅咒的光盘,但是也没玩很长时间就放在那边吃灰了。最近血源诅咒还出了 PC 模拟器,羡煞我也,现在 PS5 的用处就只有 25 年游玩道德与法治 6 了。
最近除了玩游戏,其他时候我也会出去旅个游,在朋友圈里面不方便发,我就发在掘金了。每次出去旅游完我都会算一下花了多少钱,果然发现为什么女生都喜欢去旅游了。今年主要是去了黄山,宁波,苏州和杭州的一些地方,有些是自己去的,有些是和家人一起去的,不论怎么样,天大地大,家人最大。


总结
我感觉2024年就是一个持续迭代的过程,当然在我这个年龄只要耐*就有无限可以尝试的机会,我还算年轻,还好年轻。
所以我在2025年制定了以下几个目标,方便我做目标管理,最终做到以终为始,有始有终。
- 学习篇:1、学习dubbo源码、spring boot源码,赋能原有公司的框架开发,做到有落地项目;2、学会C#/nodejs,至少可以做到能进行一些简单界面开发3、继续输出技术文档,可以做到2025年发布12篇4、看书:非开发:《小米创业思考》、《态度改变与社会影响》、《精力管理》、《金字塔原理》、《Personal development for smart people》、《原则》、《学会提问》开发:《quarkus CookBook》、《重构:改善既有代码的设计》、《编程珠玑》、《穷爸爸富爸爸》、《人月神话》、《高性能MySQL》、《架构整洁之道》争取做到一个月可以阅读完一本书,且可以真正的将书中看到的学到的进行实践,记录下来效果。5、挑一个开源项目,或者自己维护一个开源项目(既然学习完源码,不仅能在工作中有效果,也要在副业上有效果)
- 工作篇:1、考证书,公司内提供了一些行业级别证书,5月参加考试2、软考高级架构师拿下
- 生活篇:1、跑步300km,每周至少4次运动,明确一个对当前体重合适有效的训练方式。2、去华南旅游一次,去西北旅游一次,去西南旅游一次(当然在我有点钱的情况下)3、入手一辆好一点的公路自行车,准备一下全年的骑行计划。4、多去视频网站上面学习一下英语,具体精确到可以看一些海外技术书籍基本无压力5、多接触其他人,拓宽自己的社交圈子。