凤凰架构——架构师的视角
1、远程服务
远程服务调用使得返回信息变成了成功,失败和超时,后续的远程服务调用都是基于这方面的开发。
RPC的基本用处如下:1、怎么表示数据;2、怎么传递数据;3、如何表示方法
统一的RPC:简单、普适、高性能这三点,似乎真的很难同时满足。
分裂的RPC:1、朝着面向对象发展,不满足于RPC将面向过程的编码方式带到分布式,希望在分布式系统中也能够进行跨进程的面向对象编程,代表为RMI;2、朝着性能发展,代表为gRPC和Thrift。决定RPC性能的主要因素有两个:序列化效率和信息密度;3、朝着简化发展,代表为JSON-RPC,说要选功能最强、速度最快的RPC可能会很有争议,但选功能弱的、速度慢的,JSON-RPC肯定会是候选人之一。
REST需要满足如下信息:1.客户端与服务端分离(Client-Server);2.无状态(Stateless)(最重要,这是高性能分布式系统的基石之一);3.可缓存(Cacheability);4.分层系统(Layered System)(类似计算机网络的分层)5.统一接口(Uniform Interface)6.按需代码(Code-On-Demand)
RPC和rest区别是,虽然RPC和REST都可以表示远程调用,但是实际上是思想的不同;REST面向资源变成;PRC面向过程变成(其他的如面向对象编程,面向接口编程,也有其各自的意义)
REST的不足:1、面向资源的编程思想只适合做CRUD,面向过程、面向对象编程才能处理真正复杂的业务逻辑。2、REST与HTTP完全绑定,不适合应用于要求高性能传输的场景中。3、REST不利于事务支持。(如果“事务”只是指希望保障数据的最终一致性,说明你已经放弃刚性事务了,这才是分布式系统中的正常交互方式,使用REST肯定不会有什么阻碍,更谈不上“不利于)4、REST没有传输可靠性支持。(在支付等情况下可能面临更多挑战)5、REST缺乏对资源进行“部分”和“批量”处理的能力。(这技能通过新增接口实现,同一个接口频繁调用会导致限制频率)
2、事务处理
2.1本地事务
在本地事务(局部事务)还是要求ACID
2.1.1实现原子性
事务的实现原理基于ARISE理论
实现原子性和持久性的最大困难是“写入磁盘”这个操作并不是原子的,不仅有“写入”与“未写入”状态,还客观存在着“正在写”的中间状态。由于写入中间状态与崩溃都是无法避免的,为了保证原子性和持久性,就只能在崩溃后采取恢复的补救措施,这种数据恢复操作被称为“崩溃恢复”。
为了能够顺利地完成崩溃恢复,在磁盘中写入数据就不能像程序修改内存中的变量值那样,直接改变某表某行某列的某个值,而是必须将修改数据这个操作所需的全部信息,包括修改什么数据、数据物理上位于哪个内存页和磁盘块中、从什么值改成什么值,等等,以日志的形式——即以仅进行顺序追加的文件写入的形式(这是最高效的写入方式)先记录到磁盘中。只有在日志记录全部安全落盘,数据库在日志中看到代表事务成功提交的“提交记录”(Commit Record)后,才会根据日志上的信息对真正的数据进行修改,修改完成后,再在日志中加入一条“结束记录”(End Record)表示事务已完成持久化,这种事务实现方法被称为“提交日志”(Commit Logging)。
日志实现事务只是事务是实现的方法之一,其他如影子分页(shadow paging)被SQLite使用
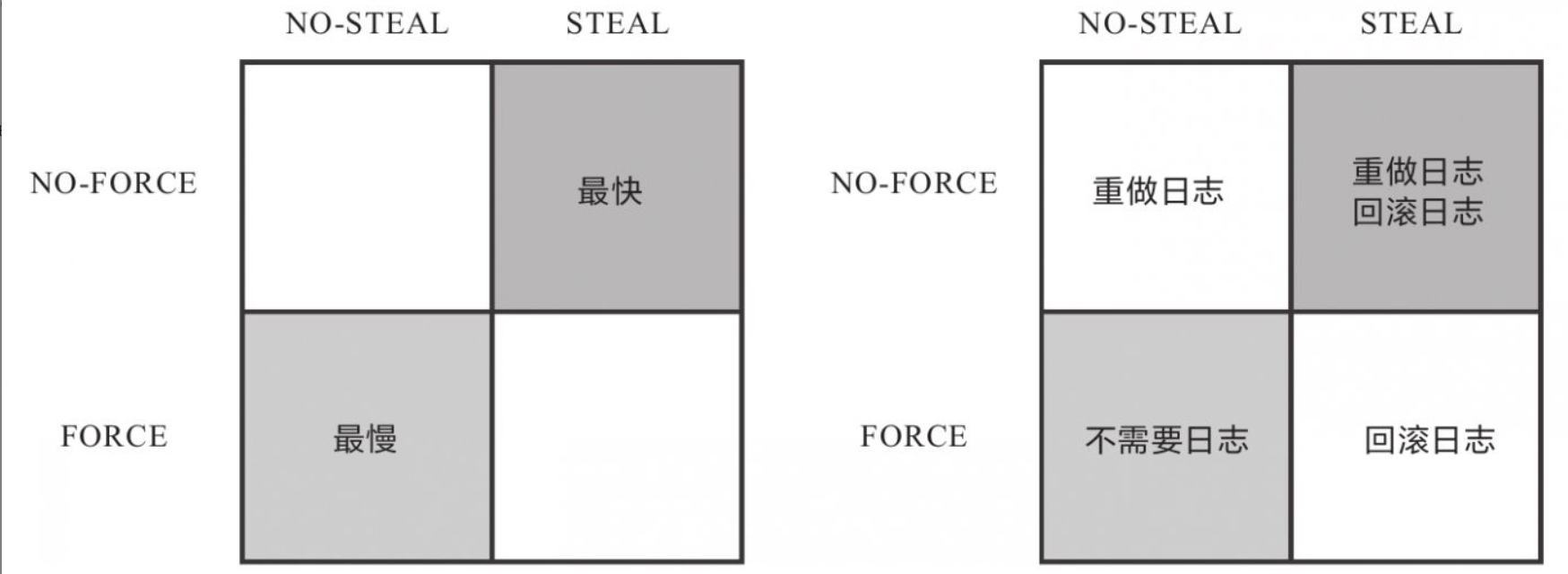
Write-Ahead Logging按照事务提交时点,将何时写入变动数据划分为FORCE和STEAL两类情况。
·FORCE:当事务提交后,要求变动数据必须同时完成写入则称为FORCE,如果不强制变动数据必须同时完成写入则称为NO-FORCE。现实中绝大多数数据库采用的都是NO-FORCE策略,因为只要有了日志,变动数据随时可以持久化,从优化磁盘I/O性能考虑,没有必要强制数据写入时立即进行。
·STEAL:在事务提交前,允许变动数据提前写入则称为STEAL,不允许则称为NO-STEAL。从优化磁盘I/O性能考虑,允许数据提前写入,有利于利用空闲I/O资源,也有利于节省数据库缓存区的内存。Commit Logging允许NO-FORCE,但不允许STEAL。因为假如事务提交前就有部分变动数据写入磁盘,那一旦事务要回滚,或者发生了崩溃,这些提前写入的变动数据就都成了错误。
Write-Ahead Logging允许NO-FORCE,也允许STEAL,它给出的解决办法是增加了另一种被称为Undo Log的日志类型,当变动数据写入磁盘前,必须先记录Undo Log,注明修改了哪个位置的数据、从什么值改成什么值等,以便在事务回滚或者崩溃恢复时根据Undo Log对提前写入的数据变动进行擦除。
Write-Ahead Logging在崩溃恢复时会经历以下三个阶段:
分析阶段(Analysis):该阶段从最后一次检查点(Checkpoint,可理解为在这个点之前所有应该持久化的变动都已安全落盘)开始扫描日志,找出所有没有End Record的事务,组成待恢复的事务集合,这个集合至少会包括事务表(Transaction Table)和脏页表(Dirty Page Table)两个组成部分。·重做阶段(Redo):该阶段依据分析阶段中产生的待恢复的事务集合来重演历史(RepeatHistory),具体操作是找出所有包含Commit Record的日志,将这些日志修改的数据写入磁盘,写入完成后在日志中增加一条End Record,然后移出待恢复事务集合。·回滚阶段(Undo):该阶段处理经过分析、重做阶段后剩余的恢复事务集合,此时剩下的都是需要回滚的事务,它们被称为Loser,根据Undo Log中的信息,将已经提前写入磁盘的信息重新改写回去,以达到回滚这些Loser事务的目的。
以上三个阶段都是幂等的
2.1.2实现隔离性
范围锁指的是一定范围内的数据不允许变更,增删改数据行都不允许出现
| 锁\事务中是否存在 | 串行化 | 可重复读 | 读已提交 | 读未提交 |
|---|---|---|---|---|
| 读锁(S-LOCK) | 操作串行执行 | √ | √ | × |
| 写锁(x-Lock) | 操作串行执行 | √ | × | × |
| 范围锁(range-lock) | 操作串行执行 | × | × | × |
| 造成问题 | 慢 | 幻读 | 不可重复读 | 脏读 |
MVCC也是为了隔离性出现的,怎么实现的
·插入数据时:CREATE_VERSION记录插入数据的事务ID,DELETE_VERSION为空
·删除数据时:DELETE_VERSION记录删除数据的事务ID,CREATE_VERSION为空。
·修改数据时:将修改数据视为“删除旧数据,插入新数据”的组合,即先将原有数据复制一份,原有数据的DELETE_VERSION记录修改数据的事务ID,CREATE_VERSION为空。复制后的新数据的CREATE_VERSION记录修改数据的事务ID,DELETE_VERSION为空。
| 字段使用\隔离级别 | 可重复读 | 读已提交 | 读未提交 | 串行化 |
|---|---|---|---|---|
| CREATE_VERSION | 总是读取CREATE_VERSION小于或等于当前事务ID的记录,在这个前提下,如果数据仍有多个版本,则取最新(事务ID最大)的 | 总是取最新的版本即可,即最近被提交的那个版本的数据记录。 | 不相关 | 不相关 |
| DELETE_VERSION | 无 | 总是取最新的版本即可,即最近被提交的那个版本的数据记录。 | 不相关 | 不相关 |
MVCC是只针对“读+写”场景的优化,如果是两个事务同时修改数据,即“写+写”的情况,那就没有多少优化的空间了,此时加锁几乎是唯一可行的解决方案,稍微有点讨论余地的是加锁策略是选“乐观加锁”(Optimistic Locking)还是选“悲观加锁”(Pessimistic Locking)。
2.2全局事务
(XA事务时对事务调度器和资源调度的整合)
graph TD A[共识协议层] --> A1(2PC/3PC) A --> A2(Paxos/Raft/ZAB) --> B[协调器高可用] A --> A3(Gossip) --> C[最终一致系统] D[事务模型层] --> D1(XA) --> A1 D --> D2(TCC) --> B D --> D3(SAGA) --> E[消息中间件] --> A2 D --> D4(AT) --> F[事务协调器TC] --> A2
2.3共享事务
共享事务”的提法和这里所列的两种处理方式在实际应用中并不值得提倡,鲜有采用这种方式的成功案例,能够查询到的资料几乎都发源于十余年前Spring的核心开发者Dave Syer撰写的文章“Distributed Transactions in Spring,with and without XA”[插图]。笔者把共享事务列为本章介绍的四种事务类型之一只是为了叙述逻辑的完备,尽管拆分微服务后仍然共享数据库的情况在现实中并不少见,但笔者个人不赞同将共享事务作为一种常规的解决方案来考量。
2.4分布式事务
ACID与CAP与BASE
flowchart LR
A[CAP理论] --> B1(CP模式)
B1[CP模式] --> B2(强一致性)
B2[强一致性] --> B3(ACID事务)
B3[ACID事务] --> B4(刚性事务)
A[CAP理论] --> C1(AP模式)
C1[CAP理论] --> C2(最终一致性,弱一致性)
C2[CAP理论] --> C3(BASE事务)
C3[CAP理论] --> C4(柔性事务)
3、透明多级分流系统与架构安全性
四层负载均衡的优势是性能高,七层负载均衡的优势是功能强。
做多级混合负载均衡,通常应是低层负载均衡在前,高层负载均衡在后。
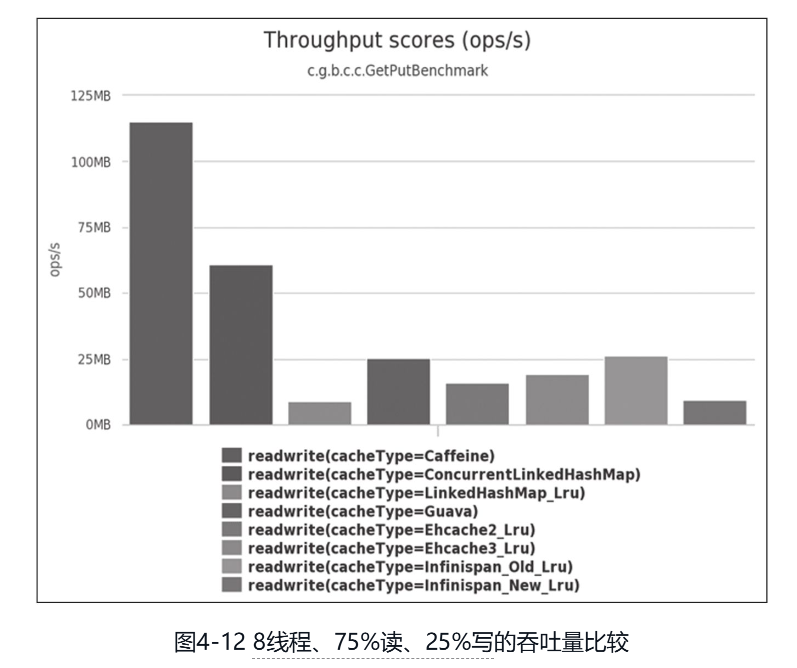
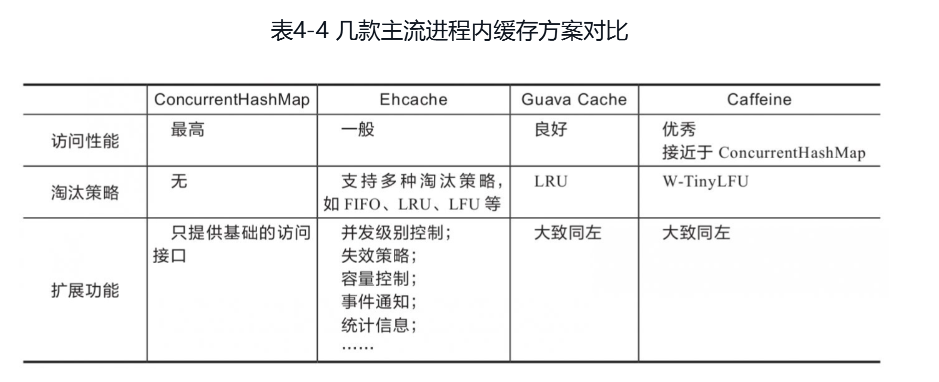
以Guava Cache为代表的同步处理机制,即在访问数据时一并完成缓存淘汰、统计、失效等状态变更操作,通过分段加锁等优化手段来尽量减少竞争。另一种是以Caffeine为代表的异步日志提交机制,这种机制参考了经典的数据库设计理论,将数据的读、写过程看作日志(即对数据的操作指令)的提交过程
缓存虽然是典型以空间换时间来提升性能的手段,但它的出发点是缓解CPU和I/O资源在峰值流量下的压力,“顺带”而非“专门”地提升响应性能。这里的言外之意是如果可以通过增强CPU、I/O本身的性能(譬如扩展服务器的数量)来满足需要的话,那升级硬件往往是更好的解决方案,即使需要一些额外的投入成本,也通常要优于引入缓存后可能带来的风险。
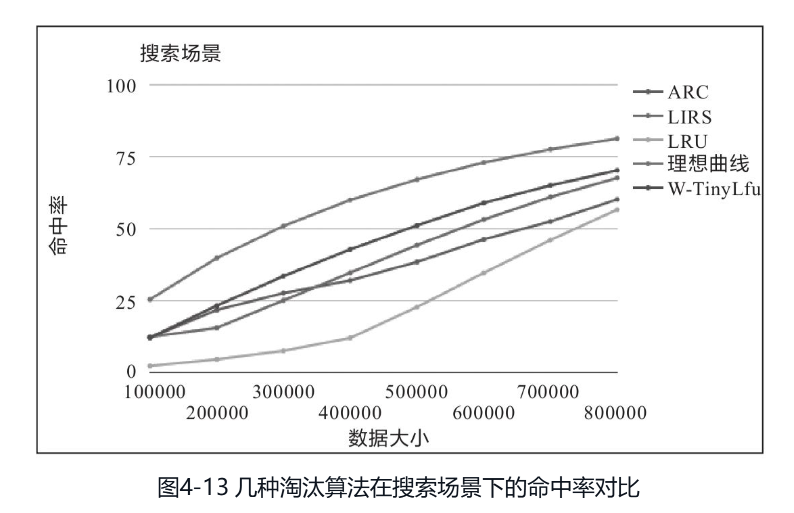
命中率与淘汰策略:FIFO;LRU;LFU;TinyLFU;W-TinyLFU;
架构安全性包括:认证、授权、凭证、保密、传输、验证