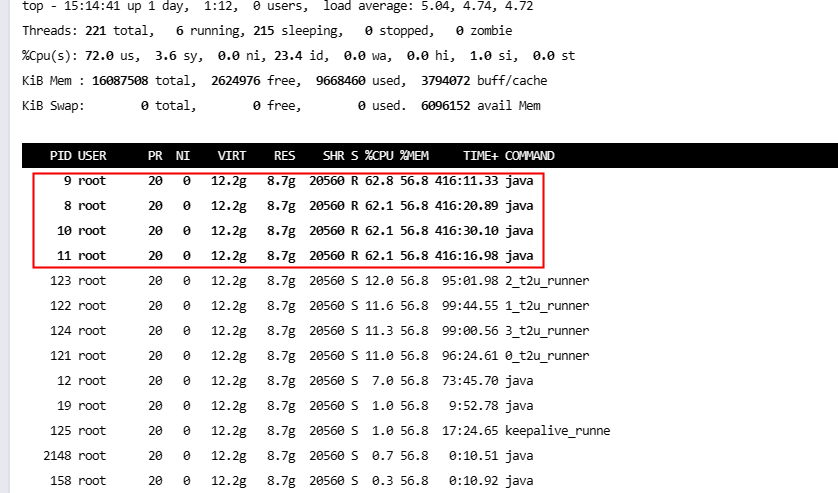
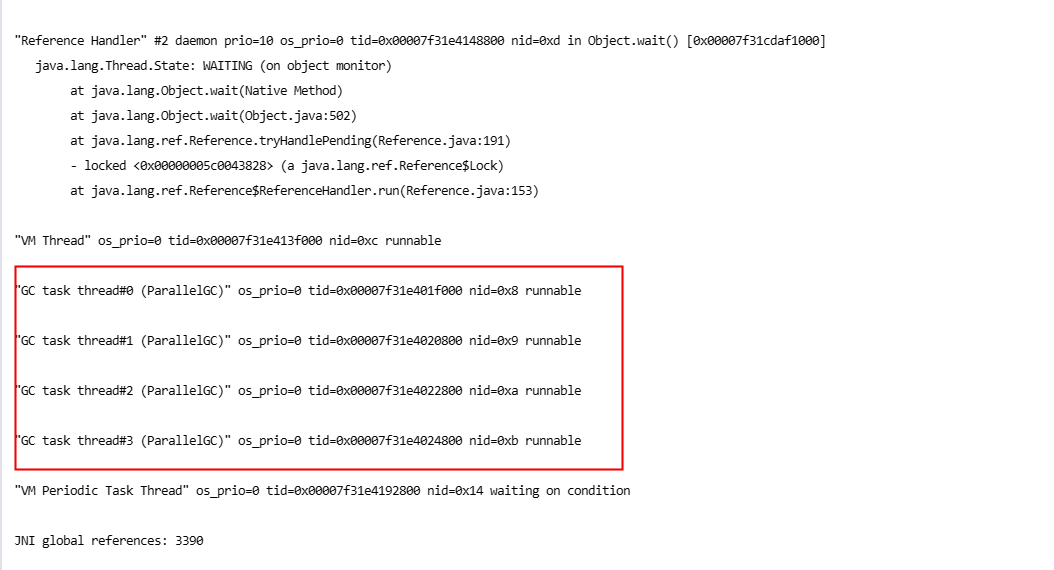
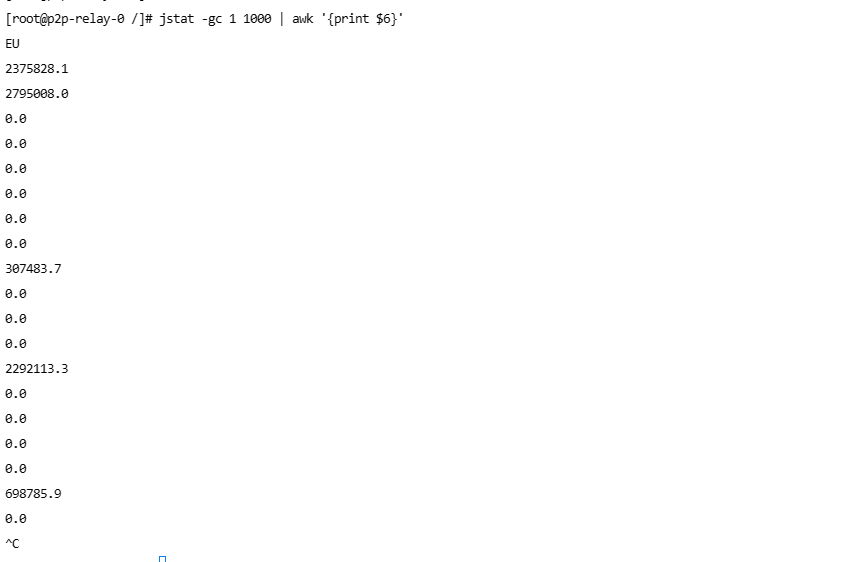
2025-03-1416:27:38.070 [34mINFO[0;39m [Thread-53990888] [CLoggerImpl.pFnLogFun: 45] [] - [p2p control] level: 3, message: [7f16197f0700][libcloud.c:7145]StartStream timeout. [50396A31-6769-5A37-5659-626251566B6A] 2025-03-1416:27:38.071 [34mINFO[0;39m [Thread-53990889] [CLoggerImpl.pFnLogFun: 45] [] - [p2p control] level: 3, message: [7f16197f0700][libcloud.c:7573][ConnectPeerDone] iTaskType(2), iIsSUccess(0), pcPeerID(50396A31-6769-5A37-5659-626251566B6A), pcPeerIP(222.222.30.55), iPeerPort(29433).2025-03-1416:27:38.078 [34mINFO[0;39m [http-nio-8998-exec-515] [CLoggerImpl.pFnLogFun: 45] [] - [p2p control] level: 3, message: [7f15f4dc4700][t2u_runner.c:265]Failed to call epoll wait, ret[0], errno[2]2025-03-1416:27:38.079 [34mINFO[0;39m [http-nio-8998-exec-515] [CLoggerImpl.pFnLogFun: 45] [] - [p2p control] level: 6, message: [7f15f4dc4700][libcloud.c:5662]MTU probe.## A fatal error has been detected by the Java Runtime Environment:## SIGSEGV (0xb) at pc=0x00007f161e0757f3, pid=1, tid=0x00007f15f4dc4700## JRE version: Java(TM) SE Runtime Environment(8.0_231-b11) (build 1.8.0_231-b11)# Java VM: Java HotSpot(TM)64-Bit Server VM(25.231-b11 mixed mode linux-amd64 compressed oops)# Problematic frame:# C [libtunnel_new.so+0x607f3] Libcloud_CreateT2URelation+0x313## Core dump written. Default location: //core or core.1## An error report file with more information is saved as:# //hs_err_pid1.log## If you would like to submit a bug report, please visit:# http://bugreport.java.com/bugreport/crash.jsp# The crash happened outside the Java Virtual Machine in native code.# See problematic frame for where to report the bug.# [error occurred during error reporting , id 0xb] [error occurred during error reporting , id 0xb] [error occurred during error reporting , id 0xb] [error occurred during error reporting , id 0xb] [error occurred during error reporting , id 0xb]